如今,基于文本的验证码依然是各大网站使用最广泛的安全机制。它通过要求用户在输入框输入随机生成的文本字符串来验证用户身份,从而防止恶意注册、暴力破解以及垃圾邮件等恶意事件发生,帮助网站保护用户数据和网络安全。提高验证码识别技术不仅可以自动地检测网站安全性,也可以从侧面改进安全策略,推动网络安全技术的进步。
笔者给大家推荐一篇利用半监督学习来识别验证码的论文—3E-Solver: An Effortless, Easy-to-Update, and End-to-End Solver with
Semi-Supervised Learning for Breaking Text-Based Captchas.

背景
早期基于图像分割的识别方法无法有效处理引入遮挡线条与重叠字符的验证码,同时也会受到字符颜色跟背景差异不统一的影响。近些年,基于深度学习识别验证码的方法虽然效果尚可,但需要精巧的模型设计与大量人工标记的数据集。因此,该论文提出了一种基于FixMatch的半监督模型识别验证码的方法,利用Encoder-Decoder与Attention机制构建端到端的基线模型识别验证码图片。
3E-Solver模型及建模流程
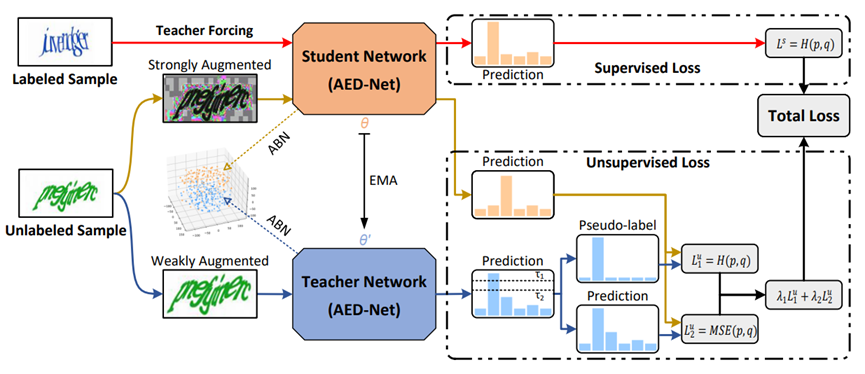
整个框架流程如上图所示,首先设计一个端到端的基线模型(AED-Net),利用编码器-解码器与注意力机制去识别验证码图片。最后,利用改进过后的FixMatch算法及少量带标签样本、大量无标签样本一同训练。
AED-Net模型结构
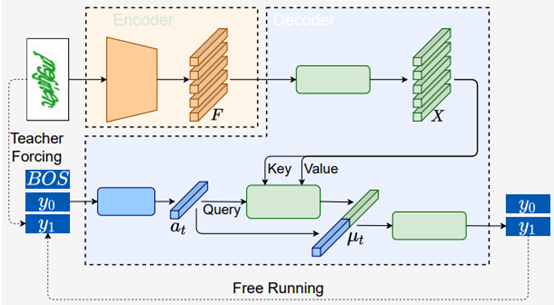
AED-Net模型分为Encoder和Decoder两部分对图片进行识别。其中,Encoder部分采用ResBlock来提取特征,并使用最大池化层来压缩Feature map的大小。论文中ResBlock残差块将特征图映射为1xWxP的特征向量,W表示图片的宽度,P表示卷积核channels数量,可以有效地提取到验证码图片从左到右的信息。
Decoder部分主要由两个GRU构成,attention和prediction,由于特征向量的感受野小于字符的特征区域面积,因此使用GRU模型可以让相邻特征向量交换信息。在解码阶段,一个GRU模块将上一个时间步的输出作为输入,利用特征向量进行训练,构造出key与value向量;另外一个GRU模块接收真实标签值做相应的embedding后构造出query向量,这一步中正是利用了teacher forcing思想,三者进行矩阵乘法与拼接操作,经过全连接层后输出模型预测结果。
对FixMatch的改进与修正
在传统的FixMatch半监督学习中,通常由模型预测弱增强样本后将具有高置信度的预测结果作为伪标签,然后利用强增强的样本与这些伪标签来训练模型。但这一方法在训练高性能验证码识别器的任务中有两个明显的缺点:
使用单个模型去预测强增强与弱增强的数据。利用Inception-v3模型进行预训练的任务中发现强增强数据与弱增强数据在模型BN层上的统计值差距过大,因此会间接影响到模型的预测值。
当模型产生高置信度预测时,才会保留伪标签。此时的阈值通常设置为较高水平0.95,这会使得一些具有低置信度的样本被浪费。
考虑到以上两个缺点,作者对FixMatch框架做出了以下几点改进:
-
Teacher forcing:利用Teacher forcing技巧进行有监督训练,使模型快速收敛同时可以最大限度地利用有标签数据。
-
自适应BN层:教师模型仅在训练阶段预测弱增强图片,因为弱增强样本更接近真实样本,BN层的统计数据更适用于测试验证码。
-
一致性损失:对于置信度较低的教师模型的预测,直接使用教师模型的softmax输出与学生模型的softmax输出值进行比较,计算均方损失函数误差。
损失函数设计
论文设计的损失函数一共包含三个部分,第一部分称为监督损失,通过教师模型指导学生模型对已有标签样本进行训练,利用分类交叉熵作为损失函数,学生模型的参数又通过滑动指数平均反馈给教师模型。第二部分称为无监督损失,当教师模型对弱增强样本的预测概率高于预先设定的阈值时,则将其看作伪标签并与学生模型对强增强样本的预测值做交叉熵损失计算。另外,为了利用到更多难学习的样本特征,如果教师模型的预测概率低于伪标签阈值但高于设定的另外一个阈值时,将其预测值的softmax与学生模型预测值的softmax做均方差损失计算,类似模型蒸馏中小模型去学习大模型预测概率分布的做法。
实验过程
实验数据准备
从Alexa.com排名前50个最受欢迎网站中挑选8个网站,收集它们的验证码作为实验数据集。对于每种验证码方案,共收集了约7200张验证码图像,手工标记2200张,其中的700张左右被用来训练模型,剩余1500张图片被用于测试。另外的5000张未标记的数据被用来作为半监督模型的学习样本。
对比评估
在经过数据集准备与训练后,模型在测试集上的表现如下图所示:
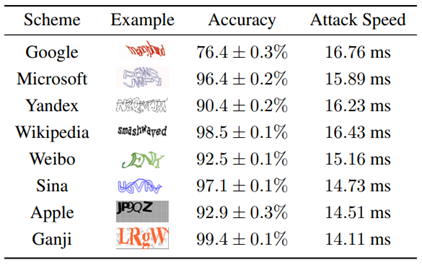
模型仅对Google网站这种很复杂验证码的识别效果较低,对其他网站验证码的识别准确率依然保持在很高的水平。
另外,作者与当下主流的验证码识别方法进行了对比,为了保证公平性,分别采用[Tang et al., 2018]提供的dataset A,[Ye et al., 2018]提供的dataset B作为实验测试数据集进行测试。最终的对比结果如下图所示:
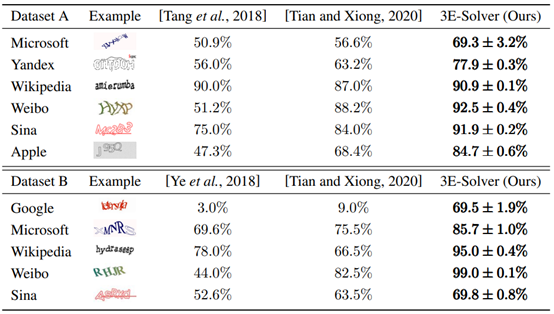
从上图可以看出,论文提出的3E-Solver方案在其他方案提供的数据集上进行测试后的结果要明显要优于这些方案。由于3E-Solver方案中的attention机制可以通过对输入数据中节点之间的全局依赖关系进行建模来,所以可以学习更多有用的特征,从而改进FixMatch对未标记样本的学习能力。即使对于复杂的Google验证码,3E-Solver在识别准确率方面相对于其他方案有很大的提升。
结论
本论文提出了一种基于Encoder-Decoder跟Attention机制的模型,结合半监督学习框架FixMatch,提出自适应BN层、Teacher forcing与一致性损失这三个改进方案,利用未标记的样本进一步提高识别能力。最后在Alexa.com中排名前50的流行网站中选择8个网站的验证码数据作为测试集进行评估。实验结果表明,3E-Solver明显优于之前的三种先进识别方案,有助于帮助安全专家重新审视基于文本验证码的设计和可用性。
参考文献
Deng, Xianwen, et al. "3E-Solver: An Effortless, Easy-to-Update, and End-to-End Solver with Semi-Supervised Learning for Breaking Text-Based Captchas."Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence. 2022.
论文地址:
https://www.computer.org/csdl/proceedings-article/sp/2023/933600b524/1Js0E2VGRhe
注:本文图片均来源于以上论文