近些年,针对政府和企业的恶意软件攻击越来越多,在数量和影响程度上都以几何倍数增加,而且这种攻击不同于普通的恶意软件攻击,它多出于政治和金融动机,专门针对政府、企业这种特定的对象,拥有极强的隐蔽性和针对性,业内称这种攻击为APT攻击,即高级可持续性攻击。
笔者推荐一篇通过机器学习和反编译来检测恶意代码重用的论文——SCRUTINIZER: Detecting Code Reuse in Malware via Decompilation and Machine Learning。
背景与相关工作
为了应对这种攻击,安全社区开始探索使用现代机器学习方法来检测APT攻击,但因为APT样本数据很稀少,所以限制了常见的机器学习技术在检测特定类型的恶意软件方面的效率。另外,由于现在的恶意软件大量使用混淆、规避等反分析技术,使得基于控制流图和编码风格这两种静态分析方法在实践中的效果都不大理想。
为了构建有效、准确的代码相似性检测方法来对现实世界的恶意软件进行检测,该论文提出了SCRUTINIZER,一种通过机器学习和反编译来检测恶意样本代码重用的方法。
SCRUTINIZER架构和建模流程
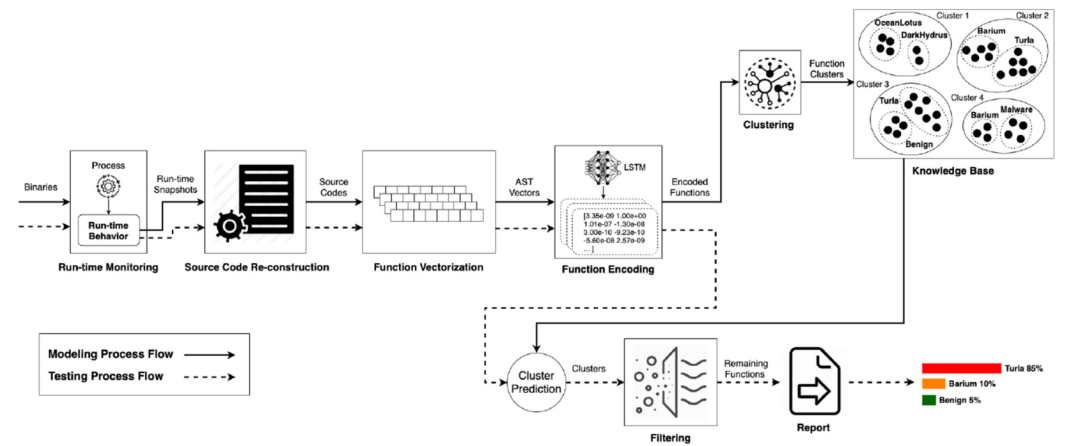
论文中提到的SCRUTINIZER架构和建模流程如上图1所示,整体流程可以分为反编译、Func2vec Encoding、编码聚类三大部分,下文将详细讲解这三个部分所做的主要工作。
反编译
首先,将给定的二进制文件放入Lastline沙盒中执行,在分析的关键时刻生成多个进程Dump。当满足以下条件之一,才被称为分析阶段的关键时刻:
1.当敏感的API被调用时,如调用创建新进程的API——CreateProcess;调用创建新文件的API——CreateFile;调用权限提升的API——AdjustTokenPrivileges
2.执行在原始PE镜像之外
3.原始PE镜像改变时
由于进程Dump中有正在分析的二进制文件的加载代码和内存块的运行时序信息,当沙箱引擎检测到满足上述条件的可疑行为时,就会获取进程Dump。论文中使用Ghidra工具将Dump文件中的内存区域映射到Ghidra的虚拟内存空间,进行后处理——将其反编译成源代码。
Func2vec Encoding
将上一步提取到的源代码中的函数映射到抽象语法树(AST)节点,从而将每个函数表征为数值向量,用它们来表征样本,并作为孪生神经网络的输入。详细的网络结构如下图所示:
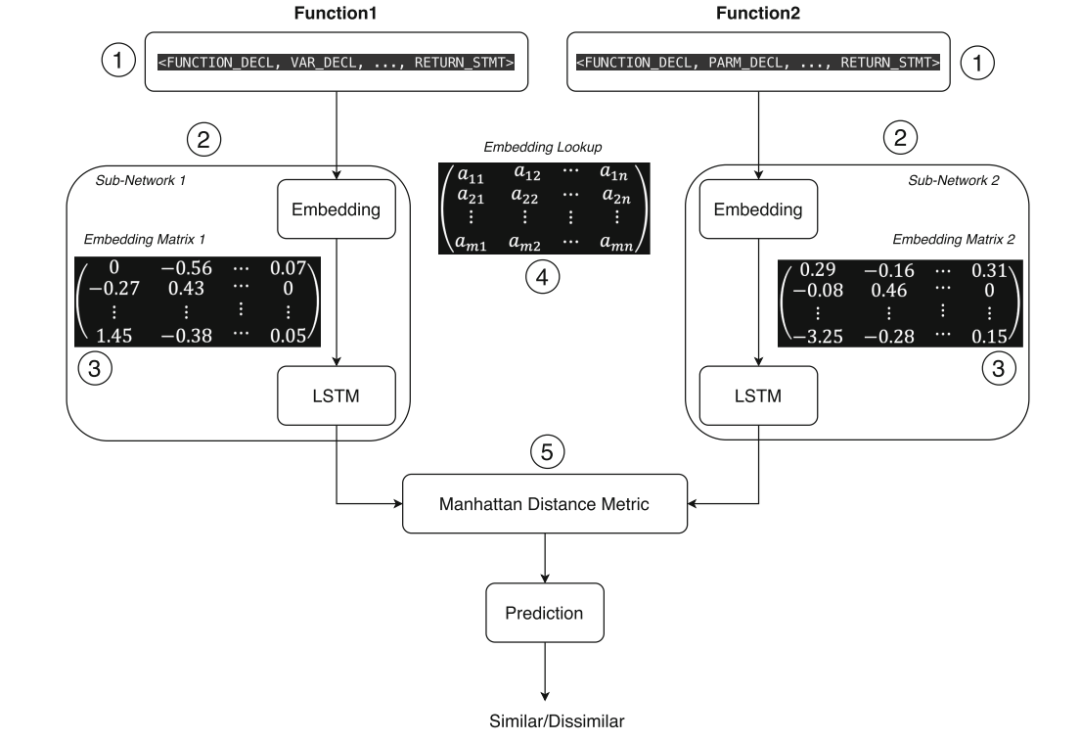
孪生神经网络(SNN)由两个或多个具有相同架构的子网络构成,它在很多领域的表现都很好,在相似性和度量学习方面效果突出。SNN接收上一步向量化的样本函数作为输入,利用长短期记忆神经网络(LSTM)作为子网络去学习样本函数的时序特征,然后利用曼哈顿距离估计两个向量之间的相似性,于是上图中的SNN其实是MaLSTM。
最后,论文为了发现相似函数,提取了经过SNN编码后每个样本函数向量的n-gram词袋特征,通过局部敏感哈希(LSH)算法对所有的函数进行散列,将相似的函数映射到相同的桶中。但在随后的研究中发现,在反编译中的代码函数存在较大差异的情况下,仅仅依赖LSH算法会造成严重误报。因此,需要结合其他方法来减少误报的情况。
编码聚类
在上一步LSH算法的基础上,论文使用HDBSCAN聚类算法对不同集群中的函数编码进行分组。与常规的聚类算法相比,HDBSCAN不需要参数调整,运行速度快且占用内存少。为了加快聚类过程,论文使用主成分分析(PCA)技术将函数编码的维度从128维减少至8维。通过实验测试,数据维度减少并不会显著影响聚类结果。
至此,论文基于恶意代码与正常样本混合的训练数据,构建了一个大型的函数代码知识库。当有新的未知样本经过SNN时,会被转换为一组函数编码向量,经过去噪处理(恶意样本和良性样本中会共享大量的代码,如:静态链接的标准库函数、全局变量初始化代码等,位于这些函数的聚类族群中则被判定为噪声,需要去除)。然后与函数代码知识库中的向量进行相似度比较,取相似度最大的几个向量作为最终的预测结果。
实验过程
实验数据
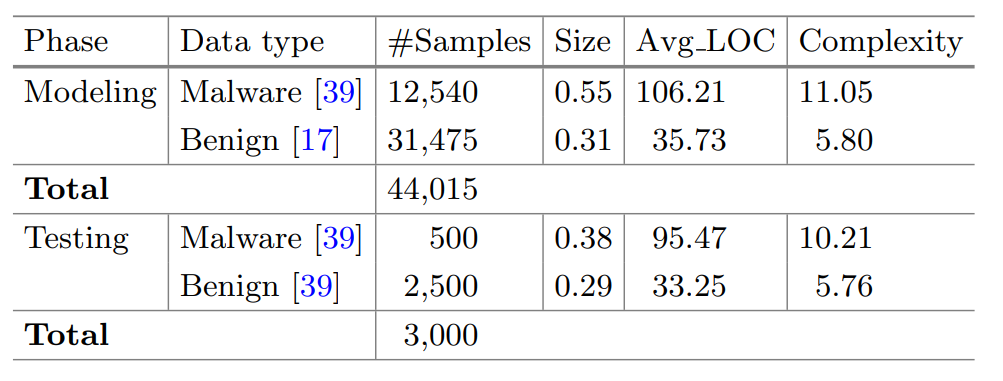
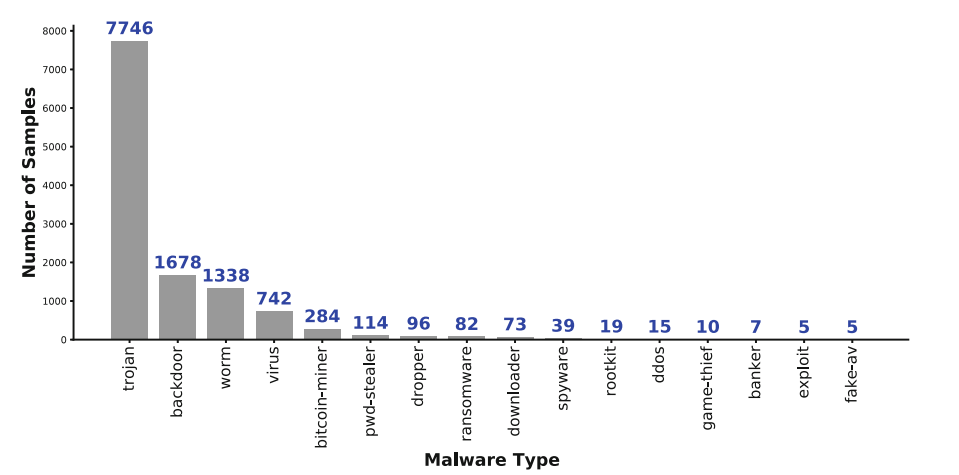
作者采用Python语言编写SCRUTINIZER框架,使用的训练集和测试集互不重叠,其中良性样本和恶意样本共计44015个,共提取了约170w个函数。训练集中的良性样本为31475个,恶意样本为12540个,测试集中的良性样本为2500个,恶意样本为500个。除此之外,良性样本主要由不同Windows版本下的DLL文件组成,恶意样本则包括12253个普通恶意样本与287个属于APT组织的恶意样本。具体数据分布如下图所示:
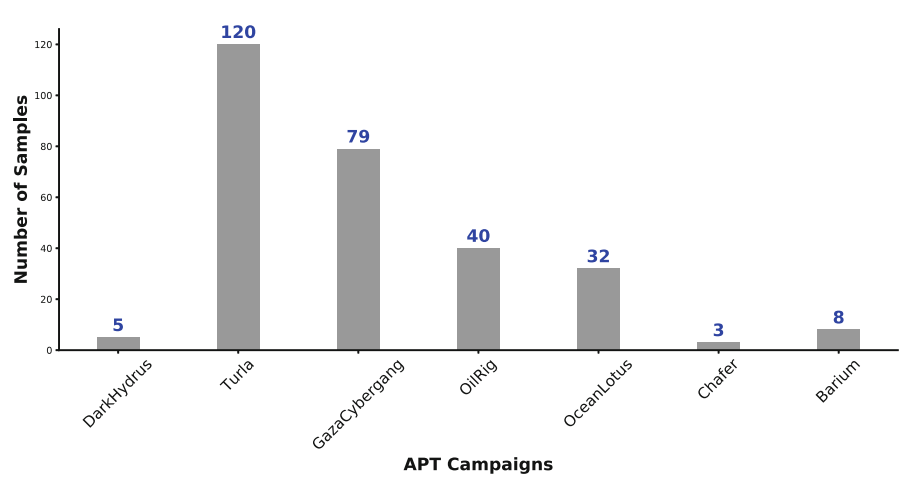
实验评估
根据前文所述,使用Ghidra反编译处理数据集的dump文件后,使用Clang工具将每个函数映射到AST向量,并对AST向量做系统调用和开发者编写区分处理。接着使用MaLSTM模型识别和编码函数对,经过噪声过滤、LSH算法处理共收集了1105000对相似和不相似的函数对。其预测误差的统计数值如下图所示:
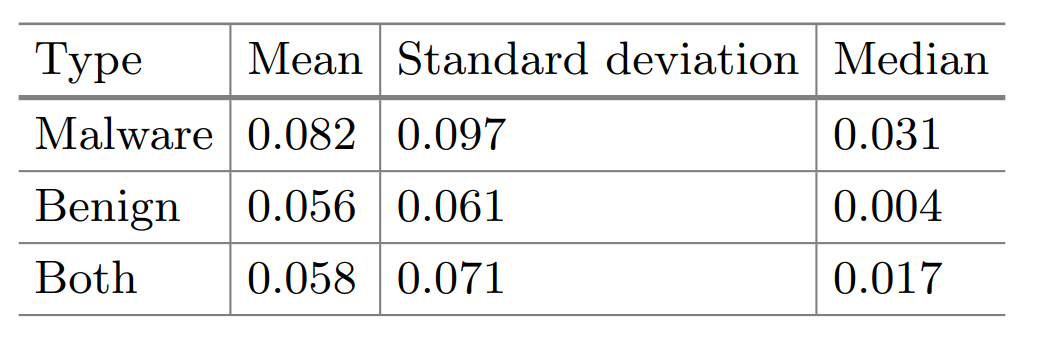
从图中结果看出,论文提出的方法效果较好。另外,作者在真实环境中随机收集了12个未知样本,人工确定其归属后,放入SCRUTINIZER系统中进行测试,最终的测试结果表明SCRUTINIZER确实可以通过函数级别的相似推理来预测未知样本的代码重用,针对未知APT攻击的效果尤其显著。其结果如下图所示:
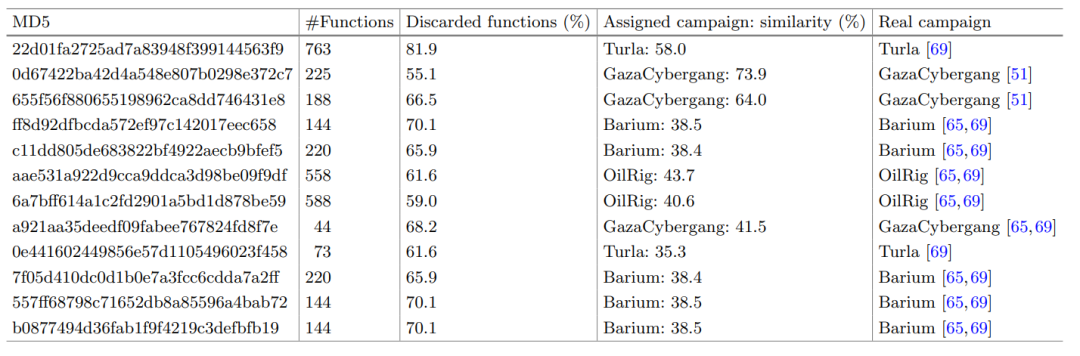
结论
论文提出了一个用于恶意代码相似性识别和活动归因的自动化系统。该系统反编译恶意和良性应用程序的二进制文件,并使用孪生神经网络对其功能进行编码。然后它将函数编码聚类到不同的组中,并利用聚类期间创建的聚类标签来分析安全公司每天收到的新样本的。作者在真实环境中部署了 SCRUTINIZER,事实证明它在APT活动的函数过滤(即逆向工程)和代码重用分析中都效果显著。并且能够识别出 12 个未发现的样本,最后将其准确地分配给正确的 APT攻击活动。
结论
Mirzaei, O., Vasilenko, R., Kirda, E., Lu, L.,& Kharraz, A. (2021, July). Scrutinizer: Detecting code reuse in malware via decompilation and machine learning. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment(pp. 130-150). Springer, Cham.
注:本文图片均来源于以上论文