当今高度信息化的时代,网络安全的重要性不言而喻。为了应对日益复杂的网络威胁,许多企业和组织都在寻求更加高效、精准的解决方案。而随着最近火热的ChatGPT出现和国内大模型的不断更新迭代,引发了无数中小企业纷纷布局各自垂直领域大模型以追赶新技术。墨云科技推出的大模型VackGPT采用P-Tuning v2架构微调训练而成,凭借其出色的性能和优势,引起了业界的广泛关注。
什么是P-Tuning v2,在网络安全领域有何优势
P-Tuning v2基于P-Tuning发展而来,先简单介绍下P-Tuning技术起源和特点。P-Tuning是旨在解决大模型的对人工构造prompts模板特别敏感问题,简单来说,就是用户输入的prompts稍微多一个词或变化一个位置,则会造成生成结果差异性很大的问题,因此在输入层设计了一种连续可微的virtual token(类似于Prefix-Tuning),目的是将输入的prompts的token转化成可学习的token。这样能更好的理解用户输入的不同形式的相同问题,相比Prefix Tuning,P-Tuning加入的可微的virtual token,仅限于输入层,并没有在每一层都加。
P-Tuning虽然解决了prompts模板敏感问题,但在一些复杂自然语言理解(NLU)任务上,P-Tuning的效果不具备通用性。实际上,预训练的参数量不能小于百亿级参数量,否则无法达到预期效果。在网络安全领域,需要结合复杂场景和多任务来解决各个子任务。例如,给出一个漏洞描述文本进行模拟渗透任务中某个关键业务信息判断时,需要考虑三个子任务:NER实体提取、漏洞类型分类和渗透优先级判定。最终需要结合其他业务逻辑来判断是否优先渗透该漏洞,并为下一步的系统决策做准备。类似的跨任务应用在网络安全中非常常见。
中小企业在垂直领域开发的专属模型时,往往难以获得百亿参数训练的GPU硬件算力,然而,P-Tuning v2技术的出现解决了上述问题。首先,P-Tuning v2最显著的改进源于对预训练模型的每一层应用连续提示,而不仅仅是输入层。深度提示调整增加了连续提示的能力,并缩小了不同参数量大模型微调的效果差距,尤其是对于小模型。其次,P-Tuningv2仅需要LLM大模型原始参数量的0.1%~3%的可优化训练参数,即可达到精调效果,更适应跨多任务学习,尤其是网络安全应用中大模型多任务学习能力要求更高。这不仅极大降低了算力成本,同时显著提升了效果。最后,除了P-Tuning v2微调框架,还有类似的框架叫做LoRA微调框架,LoRA框架同样也是冻结大模型原有参数,只微调少量的新增参数。为了对比2种框架的训练效果好坏,实际训练过程中也同样采用LoRA框架进行训练,在相同的算力资源和数据量下,经多次对比实验发现,P-Tuning v2在多次对比实验中的多任务综合评分分数要稍高于LoRA框架。
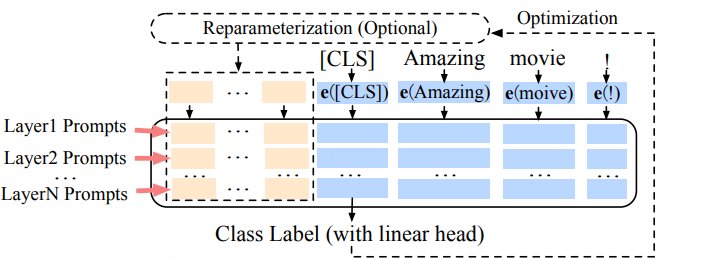
P-Tuning v2技术在网络安全领域的优势体现在多个方面。首先,它采用大模型参数,具备强大的信息处理能力和泛化能力,能够更好地应对各种复杂的网络安全问题。其次,相比于传统的调优方法,P-Tuning v2技术可以在更大范围内进行微调,更加精确地匹配特定领域的特征,从而大幅提升模型的性能。最后,该技术可以广泛应用于各类网络安全场景,包括但不限于数据泄露、恶意攻击等,为网络安全行业带来了革命性的变革。
总结
总的来说,P-Tuning v2技术以其高效、轻量化算力资源优势,已经在网络安全领域取得了显著的应用成果。随着人工智能和大数据技术的不断飞速发展,我们有理由相信,未来的网络安全行业将会更加依赖于这种高效、精准的微调技术。同时,这也预示着未来科技的发展趋势:即人工智能和大数据技术在各个领域的应用将会越来越广泛和深入。
面对未来科技的浪潮,期待更多的企业和组织能够关注并投入科技创新,探索更多的应用领域和应用场景。我们也相信,在科技力量的推动下,未来的网络安全行业将会变得更加安全、可靠、高效。我们期待着P-Tuning v2技术以及更多类似技术的不断涌现,它们将引领网络安全行业的未来发展,为每个服务商构建一个更加安全、可靠的数字世界。
参考文献
https://arxiv.org/pdf/2103.10385
https://arxiv.org/pdf/2110.07602
https://zhuanlan.zhihu.com/p/622810394