随着现代软件的复杂性和功能不断增加,软件库在Linux系统中扮演着至关重要的角色,为应用程序和系统提供了丰富的功能和支持。然而,这些软件库可能存在着未知的漏洞和潜在的安全风险,给系统带来潜在的安全威胁。在安全研究和漏洞挖掘领域,Fuzzing(模糊测试)已经成为一种广泛应用的自动化测试技术。Fuzzing通过生成大量随机或半随机的输入来模拟真实世界中的异常情况,并将这些输入提供给目标软件,以寻找潜在的漏洞和错误。
本文将带您进入Linux软件库Fuzzing的世界,向您展示如何利用Fuzzing技术,挖掘和发现潜在的安全漏洞,以提高软件库的安全性和可靠性。本文将介绍Fuzzing的基本原理,选择适当的Fuzzing工具,以及如何有效地执行Fuzzing实验。
模糊测试简介
目前网络上有大量的文章对模糊测试这项技术进行了分析总结,这里不做过多阐述。由于本次选择的目标是Linux操作系统上的软件库,其开源代码不难找到。目前网络上比较流行的针对应用层开源程序的Fuzzing工具有afl、afl++、honggfuzz、libfuzzer等,以及在这些工具基础上通过添加各种先进的功能而衍生的变种fuzzer。感兴趣的读者们可以去github上搜索相关的Fuzzing项目,如afl相关的项目Awesome-AFL。
如此多的Fuzzing工具,普通用户该如何选择呢?Google推出了可用于评估Fuzzer的开源免费服务FuzzBench,FuzzBench提供用户方便但严格的模糊测试,帮助用户们筛选出最合适的Fuzzing工具。当前较新的测试结果如下:

从这张图片可以看出,aflplusplus在两个排行榜都是第一,这意味着aflplusplus这个工具可以以更快的速度触发应用程序更多的代码覆盖率。因此,afl++就是用户开发应用层开源程序的首选fuzzing工具。
测试目标分析
由于希望助力国产操作系统,此处笔者选择银河麒麟V10操作系统上的应用软件作为测试目标。经过一番查找后,笔者决定对字体引擎方向的软件进行探索。
笔者于claude.ai上对基于Linux的字体解析引擎提问,得到的回复如下:
在Linux系统上,常见的用于字体解析和渲染的开源引擎库主要有:
- FreeType
FreeType一个流行的开源字体解析和渲染引擎,支持多种字体格式,能高质量地渲染字体。FreeType提供字体解析、贴图生成等功能。 - Fontconfig
Fontconfig是一个字体配置和自定义库,它与FreeType结合使用,用于查找和匹配系统字体。 - Cairo
Cairo是一个2D图形库,它使用FreeType进行字体渲染,可以渲染字体为图像、PDF等格式。 - Pango
Pango是基于Cairo和HarfBuzz的文字布局和渲染库,用于国际化文本处理。 - HarfBuzz
HarfBuzz专注于OpenType字体排版,可以与FreeType集成,提高文字形状的支持。
此外,还有一些轻量级字体引擎,以及图形系统自身也含有字体支持。综合利用这些库,在Linux上可以灵活地支持文本渲染和字体处理。
根据上述内容,笔者利用freetype、fontconfig做关键字,对kylin-font-viewer应用进行了粗略分析,发现导入了freetype、fontconfig相关的so文件,如图所示:

此处freetype的so版本为libfreetype.so.6.17.1,通过对freetype源码的分析,发现6.17.1版本对应freetype2.10.1版本的源码。为了初步验证,笔者查看了freetype官方的更新声明,其中提到了2.10.2开始支持WOFF2字体。笔者尝试用银河麒麟上的字体管理工具加载woff2字体失败,此时基本可以确认so文件是freetype2.10.1版本编译而来。
目标挑选好了一半,此时需要一个封装程序对freetype库函数进行调用,这是因为freetype本身是作为一个共享库供开发者使用,所以它缺少一个独立的应用。由于字体管理工具这种GUI程序在fuzzing的时候会极大地影响整体速度,这里我们不再考虑。查看fontconfig库的时候发现其内部有较多的工具实现了对freetype库的调用,其中fc-query、fc-scan这两个工具都可以用来作为Fuzzing的目标,其内部实现了对字体文件的解析。笔者使用ltrace这个工具查看了fc-query解析字体文件时对freetype库的调用流程,如图所示:
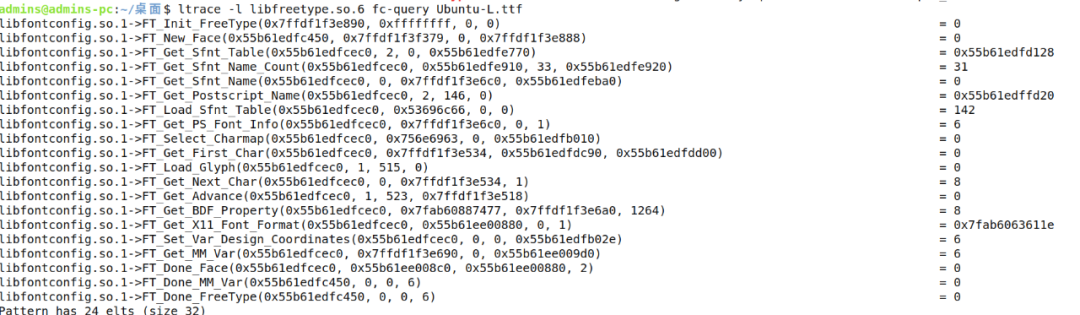
结合freetype的官方文档,笔者认为fc-query可以作为一个简单的程序来对freetype进行模糊测试,这样可以节省编写harness的时间(后续发现并非如此)。
Fuzzing初探
将afl++下载完成后,接着按照官方文档下载必要的第三方库,最后让make source-only编译需要的应用如afl-fuzz、afl-clang-fast即可。此处我们仅需fuzzing源码的应用。下面是Fuzzing过程的具体步骤:
1.编写harness
经过分析,我们直接使用fontconfig的程序fc-query进行Fuzzing。
2.编译目标
笔者在编译fontconfig的fc-query时,按照了官方标准传递编译参数,这就导致了它在链接过程会直接加载当前系统的freetype库,而系统的freetype库是未进行"代码插桩"的;在afl++中,尽量将程序打包为一个静态应用,从而避免对动态共享库进行Fuzzing,否则在统计程序覆盖率的反馈时会出现问题。

因此,正确的流程是先编译freetype生成一个插桩后的libfreetype.a文件,接下来在编译fontconfig时,将libfreetype.a文件的路径传递给LDFLAGS标志,这样生成的fc-query虽仍是一个动态链接的文件,但至少将freetype库包含在内。由于我们的目标就是对freetype进行测试,这样的结果也算是基本满足Fuzzing的需求。
为了能够更好地检测崩溃,笔者在编译的时候加入了环境变量AFL_USE_ASAN=1,如此能够在源码中插入ASAN的检测块。ASAN(AddressSanitizer)是一种内存错误检测工具,主要用来帮助发现和调试内存相关的漏洞。ASAN由Google团队创建,经过多年发展 已经成为编译器工具链和测试工具的重要组件,它可以用来检测如缓冲区溢出、内存越界访问、释放后重用、双重释放等漏洞。当前afl++提供了多个不同的崩溃检测类型如ASAN、MSAN、TSAN等等,后续还会做更多的测试来尝试寻找不同类型的崩溃。
afl本身支持输入字典来辅助提高代码覆盖率,特别是针对一些结构化信息较高的程序。通过afl的随机变异可能难以满足特定的判断条件,如特定序列的字符串、大整数、大浮点数等。通过提供一个和程序相关性较高的字典文件,可以有效提高程序的代码覆盖率。为了简化这一过程,afl++支持在编译目标应用时,会直接生成相关的字典文件,方便在后续的Fuzzing过程中使用时添加对应的环境变量export AFL_LLVM_DICT2FILE=/full/path/to/new/file.dic。在编译结束后,即可看到由编译器生成的字典文件。
为了提高Fuzzing速度,笔者选择在fc-query源码中插入__AFL_INIT、__AFL _ LOOP等代码来支持对目标程序的持久化测试,这样可以大幅提高Fuzzing速率。
3.寻找样本
笔者这里直接使用了MozillaSecurity的样本库。样本的选择对afl++这种模糊测试工具至关重要,合适的样本可以帮助afl找到更多关键的覆盖路径,以此提高Fuzzing找到1个或多个有效crash的成功率。
4.样本优化
笔者这里使用了afl-cmin、afl-tmin这两个工具对样本进行精简,其中afl-cmin主要用来排除触发相同代码覆盖率的样本,保证每个样本都能触发独特的覆盖率路径;afl-tmin则用来对样本进行最小化,同时保证触发的覆盖率路径不变。在afl++官方文档也提到,尽量使用体积小的样本,这样Fuzzing的速度会较快,而较大体积的样本可能会极大拖慢Fuzzing速度。因此,如果在样本数量不是非常多的时候,笔者建议依次使用这两个工具对输入样本进行优化。由于afl-tmin这个工具比较消耗时间,使用者可以根据实际情况对特定的样本进行优化而不必进行全部优化,至少要使用afl-cmin工具对重复样本进行排除。
5.运行Fuzzing
为了提升Fuzzing效率,afl提供了几个应用程序来修改操作系统配置,从而提升效率,如afl-persistent-config、afl-system-config等程序,同时afl建议程序运行在挂载ext2和noatime选项的文件系统中,这样可以最大化提高Fuzzing速度。
由于测试目标是64位可执行程序,并且在编译时加入了ASAN检测,因此在Fuzzing时必须添加-m none的参数避免afl由于申请过大内存而退出。同时为了提高Fuzzing效率,这里可以选择多核Fuzzing,即通过同时运行多个fuzzer进程来加速。afl中通过-M、-S参数来实现并行Fuzzing,并通过-o这个参数指定的文件夹来实现变异文件队列共享,也就是把其它fuzzer进程找到的新路径文件添加到自身的变异队列中。同时可以为每个fuzzer进程配置不同的变异策略,笔者一般为主进程通过-D参数配置deterministic模式,而辅进程则通过-p 参数配置不同的调度策略。前面在编译时生成了字典文件,可以通过-x参数使用。如下是一个简单的bash脚本示例,通过screen这个工具来并行运行多个afl-fuzz进程,并且可以随时通过screen来查看特定窗口的状态。
#!/bin/sh
screen -dmS main afl-fuzz -D -x ft.dic -i inp1 -o output1 -t 1000 -m none -M main1 -- ./fc-query @@
screen -dmS sess0 afl-fuzz -x ft.dic -p explore -L 0 -i inp1 -o output1 -t 1000 -m none -M sess0 -- ./fc-query @@
screen -dmS sess1 afl-fuzz -x ft.dic -p fast -L 0 -i inp1 -o output1 -t 1000 -m none -M sess1 -- ./fc-query @@
screen -dmS sess2 afl-fuzz -x ft.dic -p coe -L 0 -i inp1 -o output1 -t 1000 -m none -M sess2 -- ./fc-query @@
6.监控Fuzzing进度
当前,afl++提供了屏幕状态以及其它一系列工具用来监控整个Fuzzing过程的进度。如下图所示:
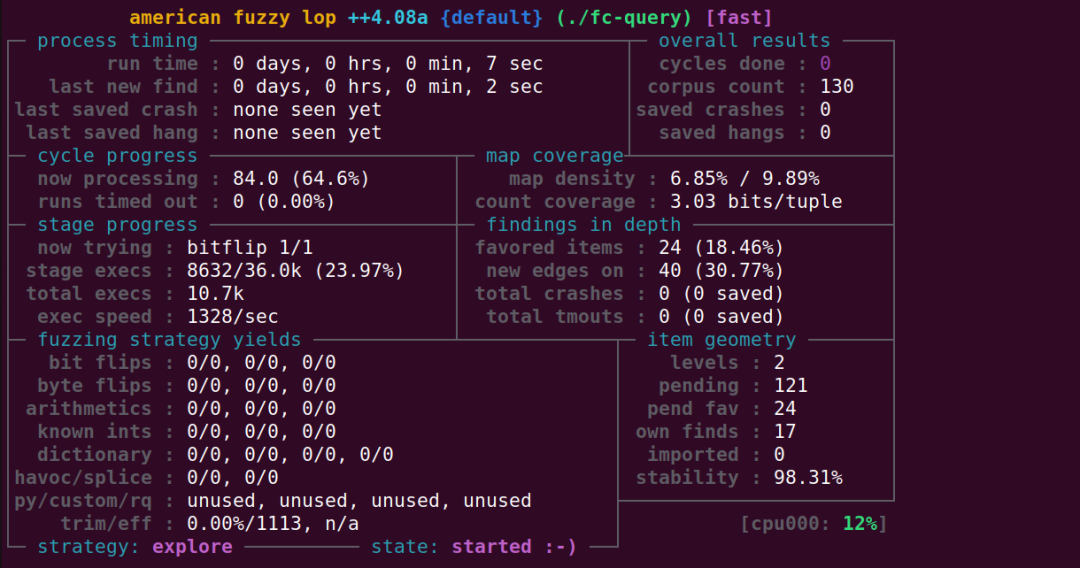
一般我们只需关注last new find、cycles done、saved crashes、map density几个值即可。
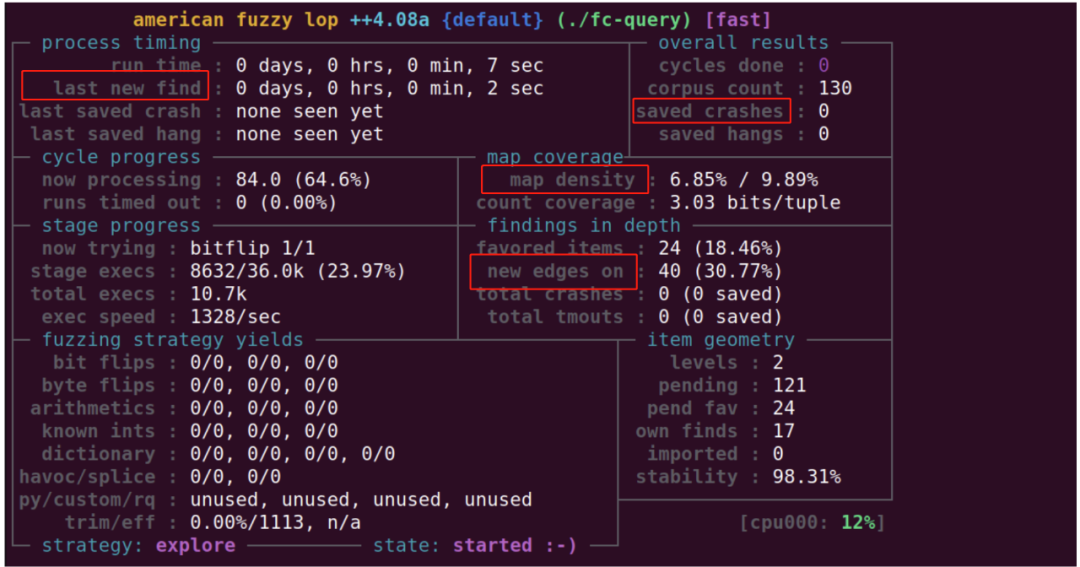
其中last new find代表上一个找到的新路径距离当前的时间;saved crashes代表保存的崩溃样本,这也是我们最希望看到的;map density根据官方解释是当前样本触发的edge比例同所有输入样本触发的edge比例的值,这仅仅是一个粗略的覆盖率统计数据,如果这两个值较低,意味着对目标的Fuzzing还有较大的提升空间。如果较长时间没有找到新的路径,此时可能需要停止Fuzzing,来找找更深层次的原因了。
同时afl++提供了afl-whatsup、afl-showmap等工具对fuzzer的运行状态进行分析。afl-whatsup可以迅速查看每个fuzzer的运行状态以及摘要信息。afl-showmap可以输出整个输出目录的样本触发的整体代码覆盖率。
7.分析结果
这里主要对Fuzzing过程中找到的crash进行分析。经过了一段时间的运行,我们对找到的crash进行查看:发现由于使用了多个Fuzzing进程,每个进程都有着接近100多个crash。为了较快地对crash进行去重,这里笔者写了一个对crash去重的bash脚本,其主要逻辑是对特定目录的crash文件进行处理,分析ASAN输出的函数调用栈,通过调用栈的不同来筛掉相同的crash。脚本如下:
#!/bin/bash
output_dir="md5output"
mkdir -p "$output_dir"
md5_file="md5.txt"
outfile="file.txt"
# 清空 MD5 文件
> "$md5_file"
# 遍历 file 目录下的所有文件
for file in crash/*; do
# 执行 fc-query 命令并获取输出
result=$(./fc-query "$file" 2>&1)
# 提取 '#' 后的所有内容
matches=$(echo "$result" | grep -o '#.*')
matches=$(echo "$matches" | awk '{print $4}')
# 计算提取内容的 MD5 值
md5=$(echo "$matches" | md5sum | awk '{ print $1 }')
# 判断 MD5 是否已存在
if grep -Fxq "$md5" "$md5_file"; then
echo "File: $file, MD5: $md5 (duplicate)"
else
echo "File: $file, MD5: $md5 (new)"
echo "$md5" >> "$md5_file"
echo "$file" >> "$outfile"
# 将执行命令的输出保存到文件
echo "$result" > "$output_dir/$md5.txt"
fi
done
官方也提供了工具用来对crash进行分析,如使用afl++的crash exploration模式对崩溃进行探索,试图确认崩溃的最小样本以及崩溃样本对应用程序的控制范围(如是否能够越界读取、写入某些内存等);还有casr工具用来对ASAN产生的崩溃报告进行分析、分类……这里不再详细介绍,感兴趣的同学可以去尝试。
为了更深入地分析漏洞,笔者推荐用gdb配合gef、peda等插件对程序进行动态调试分析,可以较为清晰地了解崩溃的原因。本次Fuzzing找到的漏洞是一个任意地址读取漏洞,函数调用栈如下:
#0 0x7fae84a16901 in memcpy string/../sysdeps/x86_64/multiarch/memmove-vec-unaligned-erms.S:222
#1 0x562e6cdef6f1 in __asan_memcpy
(/home/admins/fuzzing_freetype/bin/fc-query+0xa16f1) (BuildId: f3d22b379d299b1edc47e8a2ecbf93b372f0ffd1)
#2 0x7fae84ec8882 in TT_Vary_Apply_Glyph_Deltas /home/admins/fuzzing_freetype/freetype-2.10.1/src/truetype/ttgxvar.c:3865:9
#3 0x7fae84ec1608 in load_truetype_glyph /home/admins/fuzzing_freetype/freetype-2.10.1/src/truetype/ttgload.c:1759:17
#4 0x7fae84e896ee in TT_Load_Glyph /home/admins/fuzzing_freetype/freetype-2.10.1/src/truetype/ttgload.c:2910:13
#5 0x7fae84e896ee in tt_glyph_load /home/admins/fuzzing_freetype/freetype-2.10.1/src/truetype/ttdriver.c:475:13
#6 0x7fae84e26cb0 in FT_Load_Glyph /home/admins/fuzzing_freetype/freetype-2.10.1/src/base/ftobjs.c:949:15
#7 0x7fae84e26546 in FT_Get_Advances /home/admins/fuzzing_freetype/freetype-2.10.1/src/base/ftadvanc.c:161:15
#8 0x7fae85137dd1 in FcFreeTypeSpacing /home/admins/fuzzing_freetype/fontconfig-2.13.1/src/fcfreetype.c:2392:11
#9 0x7fae85134f1e in FcFreeTypeQueryFaceInternal /home/admins/fuzzing_freetype/fontconfig-2.13.1/src/fcfreetype.c:2004:15
#10 0x7fae8513661a in FcFreeTypeQueryAll /home/admins/fuzzing_freetype/fontconfig-2.13.1/src/fcfreetype.c:2223:8
#11 0x562e6ce2b3a5 in main /home/admins/fuzzing_freetype/fontconfig-2.13.1/fc-query/fc-query.c:158:7
#12 0x7fae8497bd8f in __libc_start_call_main csu/../sysdeps/nptl/libc_start_call_main.h:58:16
#13 0x7fae8497be3f in __libc_start_main csu/../csu/libc-start.c:392:3
#14 0x562e6cd6d494 in _start (/home/admins/fuzzing_freetype/bin/fc-query+0x1f494) (BuildId: f3d22b379d299b1edc47e8a2ecbf93b372f0ffd1)
原因是在ttgxvar.c中的 TT_Vary_Apply_Glyph_Deltas函数并没有对blend->tuplecoords变量的有效性进行判断,如果blend->tuplecoords为空,那么memcpy函数的第二个参数即目标地址可以被tupleIndex、blend->num_axis这两个变量控制,而这两个变量的值则是从字体文件中读取的,因此这是一个任意地址读的漏洞。
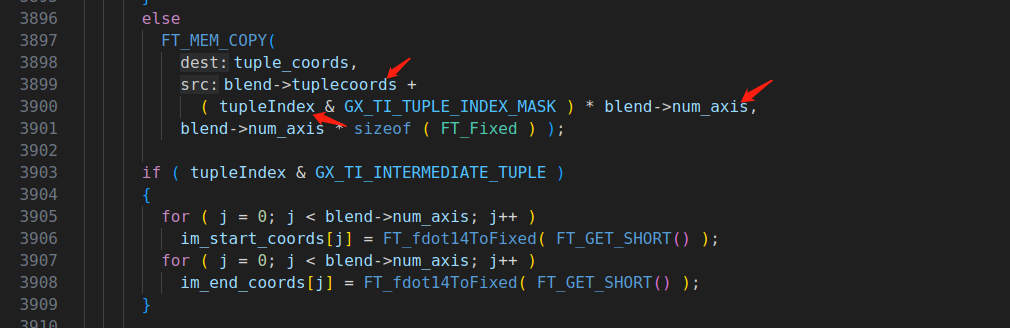
在2.10.2版本中,该漏洞已经被修复,但由于银河麒麟、ubuntu 20.04等系统依旧使用的是旧版本的freetype库,因此在该系统中还是会触发崩溃。目前我们已经向官方提交了漏洞报告,官方确认将在下个版本中修复,该漏洞目前仅能导致应用崩溃且无法造成更完整的利用,对系统造成的危害并不大。
8.优化
在整个Fuzzing过程运行了两天后,我们发现fuzzer寻找新路径的效率明显降低。这里可以用afl-plot这个工具来查看Fuzzing的效果:
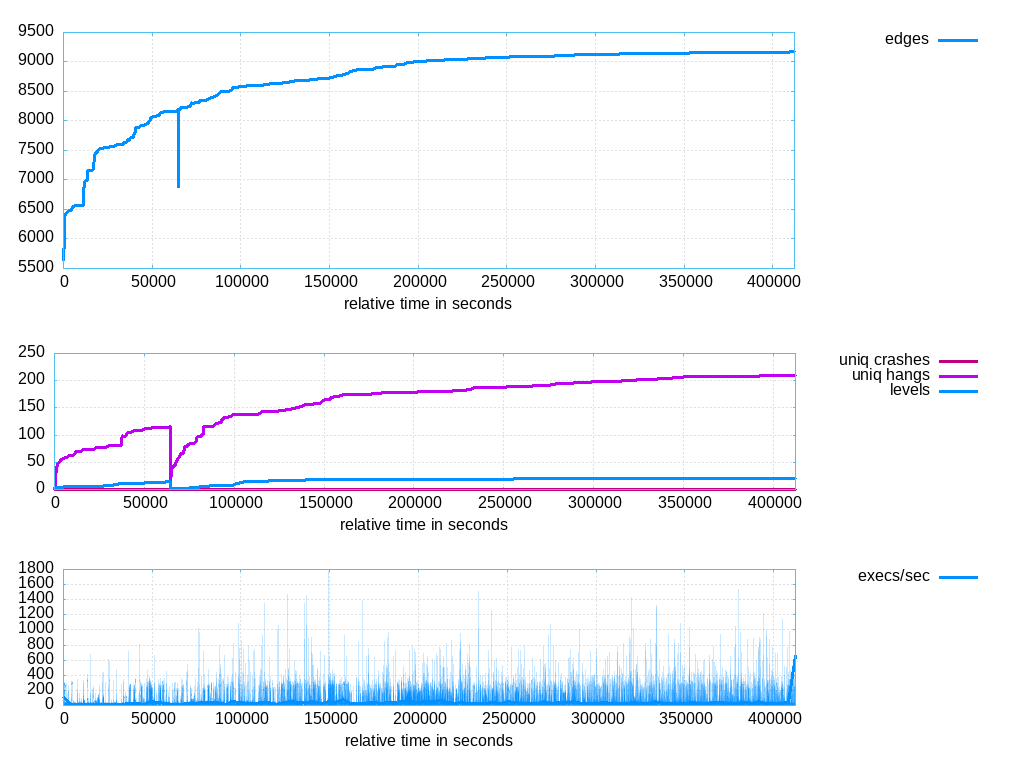
可以看到,经过一段时间的Fuzzing,fuzzer寻找新edge的覆盖率的速度已经明显变慢,此时就需要对目标应用进行更细致的分析,来提高发现新的edge的成功率。
这里笔者从整个应用的代码覆盖率范围入手,查看具体哪部分代码没有被测试到。目前有一些工具如afl-lcov等,可以支持在afl运行时实时输出特定样本的覆盖代码函数以及行数,但是不便于查看当前所有的样本产生的覆盖率。由于afl-lcov本质上是调用了lcov这个工具来生成代码覆盖图,因此笔者直接选择用lcov工具生成所有样本的代码覆盖图。
首先使用gcc配合特定的编译参数-fprofile-arcs -ftest-coverage来生成目标程序,这样每次运行目标程序后就会生成对应的覆盖率统计数据。同时笔者编写了一个脚本用来快速生成包含覆盖率反馈信息的网页:
lcov -d ./ -z
lcov -c -i -d ./ -o init.info
directory="/home/admins/fuzzing_freetype/freetype-2.10.1/out2/*/queue"
for file in $directory; do
for file2 in $file/*;do
./fc-query_cov "$file2"
done
done
lcov -c -d ./ -o cover.info
lcov -a init.info -a cover.info -o total.info
lcov --remove total.info '*conftest*' -o final.info
genhtml -o cover_report1 --legend --title "lcov2" --prefix=./ final.info
这个脚本能够遍历特定目录下的所有文件并通过编译好的程序执行,随后将生成的覆盖率数据利用genhtml生成对应的可视化网页,如下:
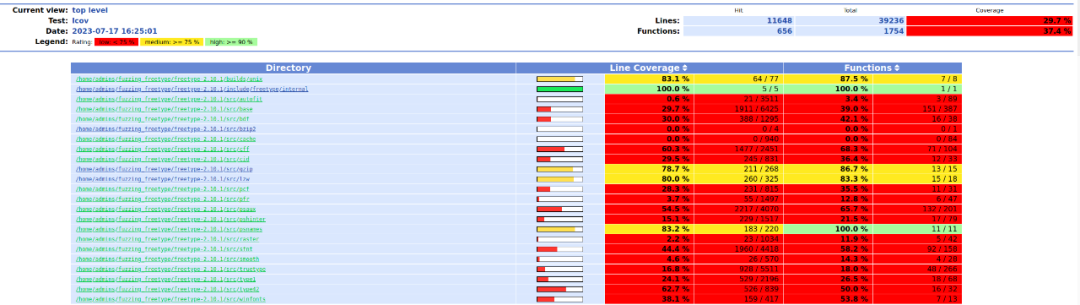
可以看出,整个Fuzzing过程的覆盖率低于30%。接下来就需要深入分析下目标函数代码,了解覆盖率低的成因。经过深入分析,笔者发现覆盖率较低的原因有两个:
1.样本覆盖不足,缺少bdf、pcf等字体格式的样本。笔者通过查看这部分样本的代码覆盖率,发现大部分都没有通过对输入格式的检测,因此需要搜集更多的样本来触发新的路径。
2.fc-query本身对freetype库的调用存在限制,由于freetype库中有大量渲染字体的代码,而fc-query通过设置flags来禁用对应代码的调用,因此我们需要找更适合Fuzzing的harness应用。
3.还有很多freetype的api没有被调用,fc-query本身并没有对这部分api的调用,这也要求我们去寻找更适合Fuzzing的harness应用。
Fuzzing进阶
在第一阶段的Fuzzing过程结束后,我们对Fuzzing的结果进行了分析,特别是针对代码的覆盖率部分,得到的结论是:相当一部分代码在Fuzzing过程中没有被触发。为了解决这个问题,我们通过对以下优化步骤来进一步提高整个Fuzzing的覆盖率。
样本优化
afl这种基于变异的模糊测试工具,本质上非常依赖有效样本来提高对目标程序的探索路径,实现更高的代码覆盖率。因此样本越丰富,越能提高整个Fuzzing的效果。针对freetype 2.10.1版本中支持的字体类型,从互联网上对这些字体进行了搜集,基本上保证覆盖了freetype所支持的所有字体格式,通过进一步的Fuzzing测试,笔者发现确实可以有效提高整个程序的代码覆盖率。如下图所示,之前针对type1格式的字体,由于缺乏样本,基本难以靠变异来通过type1的字体格式检测,而在加入了对应的样本后,覆盖率得以提高。
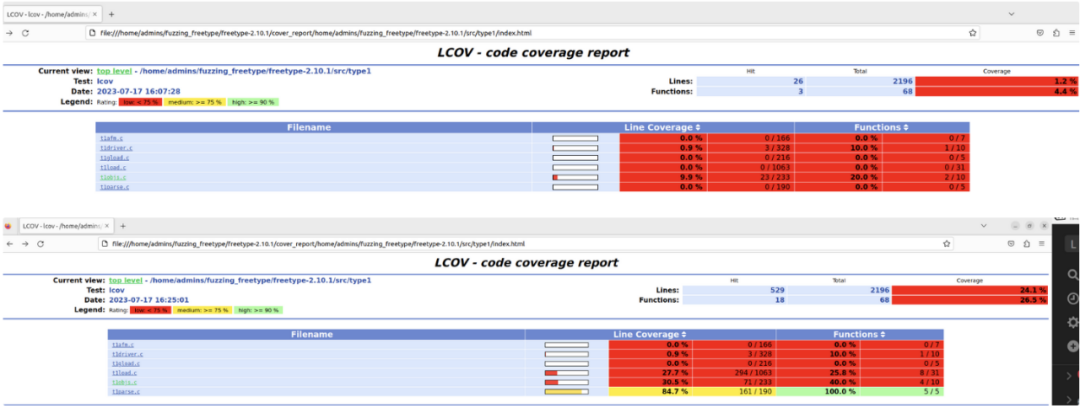
针对开源应用,我们有比较好的工具来分析整个应用程序的覆盖率,可以直观地查看没有被覆盖到的代码文件、函数名、行号等信息,为我们寻找更多样本提供思路。那么对于闭源应用,我们又该如何寻找更多更合适的样本?这里有一个取巧的办法,就是寻找与闭源应用同类型的开源产品,利用当前样本对该开源产品进行代码覆盖率统计,如果样本没有覆盖到开源产品,那么也肯定不会触发闭源应用的功能,这也算一个寻找更合适样本的思路。当然现实环境产品更加复杂,产品之间功能可能也并不相似,这种方式实施起来的效果也可能大打折扣。因此,针对闭源应用,另外一个选择就是基于生成的模糊测试工具,如peach、FormatFuzzer等,这就需要你对目标格式、结构等有一定的了解,能够针对性地编写Fuzzing引擎所需的模板文件。当然,如此多的工具能够联合起来自然是如虎添翼,如FormatFuzzer支持和afl进行集成,在保证变异种子复杂性、有效性的基础上提供给afl++,让其能够触发更多的代码路径;缺点就是比较费时费力,需要研究员花费更多的精力在处理目标结构数据上,如果当前的Fuzzing过程遇到了瓶颈,也可以尝试这种方式来突破。
harness程序优化
由于之前找到fontconfig中的程序对freetype的调用存在较多限制,为了能更多的触发在freetype中的函数调用,我们在这里分析了多个freetype-demos中的命令行程序,如ftbench、ftview等,可以通过命令行的对字体进行测试、微调、渲染。但由于渲染时会调用图像引擎对字体进行图像加载,带来巨大的性能损耗,需要进一步修改代码来更有效的进行Fuzzing。
因此尝试对整个字体渲染流程进行分析,筛除不必要对第三方库的函数调用,优化整个程序的执行流程,去除persistent模式中因为添加__AFL_LOOP函数导致的程序异常崩溃,针对部分冷门的freetype导出函数进行调用,最终形成了一个魔改版ftbench程序。
在网上搜索相关资料的时候发现Google团队很早就对freetype2的库进行了Fuzzing测试,并且集成到了oss-fuzz项目中,并且对freetype2进行Fuzzing的代码覆盖率达到80%以上。笔者出于好奇查看了他们的harness程序,发现他们基本实现了对当时freetype2版本所有导出函数的调用,配合freetype2所支持的所有字体样本,能达到80%的覆盖率也确实是很有可能。覆盖报告如下图所示:
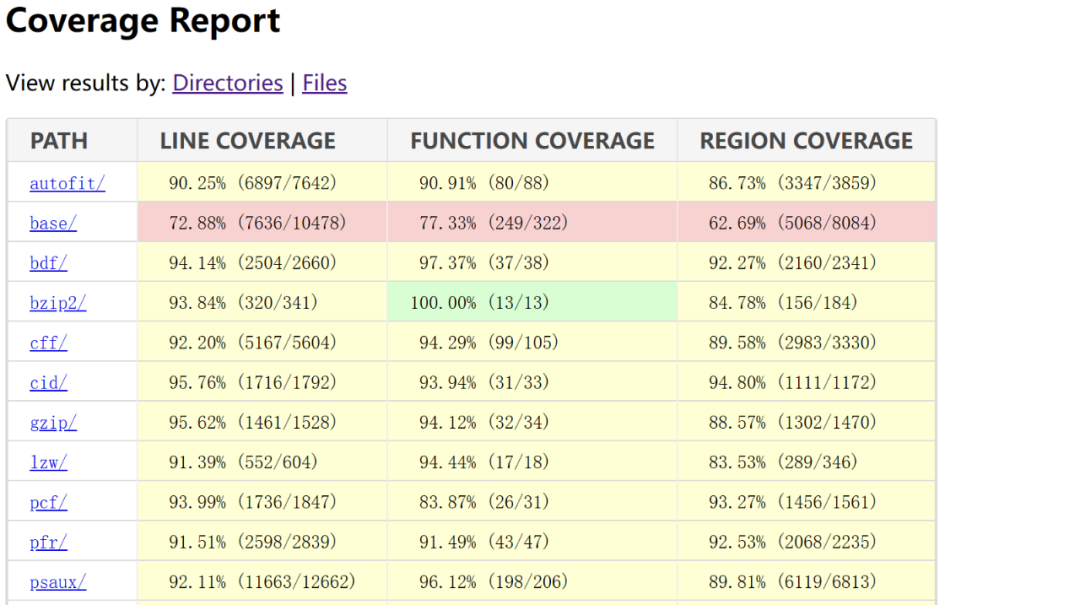
虽然说覆盖率没有100%还是有继续Fuzzing的余地的,但是这意味你需要更深入地分析代码没有被覆盖的原因,由此来不断更新harness程序或者填充新的样本。这需要耗费大量的时间、精力,而且产出新漏洞的几率并不大,建议新手避坑。当然,它还是有产生新漏洞的情况,比如CVE-2020-15999,这个freetype2漏洞并没有被oss-fuzz的程序集覆盖。因此想要在一些复杂项目中寻找漏洞,一个巧妙的思路就是查看当前社区对该项目的Fuzzing代码覆盖率程度,寻找尚未被覆盖到的代码,对这部分代码进行Fuzzing,笔者之前在研究Linux内核Fuzzing的时候同样沿用了这个思路,并在多个文件系统中找到了漏洞。
编译目标优化
afl相比afl提供了更多的编译选项来优化Fuzzing过程。比如采用afl-clang-lto编译器对目标应用进行编译,这样可以有效减少覆盖率检测时边碰撞的概率,针对大型、复杂的软件尤其有效。同时使用COMPLOG 模式可以解决变异的样本难以匹配程序中大整数、魔数等问题,进一步提高代码覆盖率。在编译afl的时候需要选择较新的llvm版本,才能生成afl-clang-lto编译工具,在编译目标时选择该工具,才可以使用afl++提供的各类优化特性,同时开启针对Fuzzing优化的环境变量配置,如AFL_LLVM_CMPLOG=1。此外,开启AFL_LLVM_CMPLOG选项时生成的目标程序,最好在afl-fuzz命令中通过-c 参数提供编译好的目标程序文件,尽量避免直接作为Fuzzing目标,这样会降低Fuzzing速度。同时afl-clang-lto编译的目标会自动保存目标程序中可以用来作为字典的数据,而不需要通过-x进行导入,在实际测试过程中发现afl-clang-lto的编译时间明显增长。
同时前面提到的llvm的各种安全检测工具(sanitizers)如ASAN、MSAN、UBSAN等,可以在编译时通过配置AFL_USE_ASAN=1的环境变量来使用,这里分别编译采用了ASAN、MSAN、UBSAN检测方式的三个目标程序,分别使用相同的种子库对三个程序进行Fuzzing。一种简单的应用方式是在多核Fuzzing中,给辅核Fuzzing进程配置不同的编译目标,由于afl++在插桩时会避开ASAN、MSAN的代码,因此程序获取到的覆盖率反馈是一致的。
笔者认为使用不同的sanitizers来对目标进行Fuzzing还是很有必要的,比如在Fuzzing过程中触发了一些特定的代码区域,而这部分代码中存在一个变量未初始化漏洞,但是你用ASAN插桩的应用根本不会有任何提示,这样就会错过发现这个漏洞的机会,因此尽可能多的使用更多的sanitizers来检测不同类型的漏洞,能够提高整个Fuzzing过程的有效产出。
符号执行探索
Hybrid Fuzzing(混合Fuzzing)是学术界和工业界一直探索的方向,通过符号执行技术来灵活地探索程序的不同路径和条件,经反馈后生成更多更有效的测试用例,可以有效提高Fuzzing的效率。笔者也尝试了多个工具来进行在实际应用场景中的探索。
首先是源码符号执行工具symcc,它利用llvm编译器在编译目标程序时插入符号化代码,用来搜集程序运行时的符号信息。和之前的符号执行引擎相比,它们采用了在编译期一次性植入符号化代码,从而减少了将代码转换为中间语言,对中间语言进行符号化的运行开销,因此symcc的标题就是Don’t interpret, compile,即不要在解释阶段执行符号化,而是在编译阶段做这件事。这种方式可以有效提高符号化程序运行的速度。
笔者在按照官方的文档进行编译后,使用了qsym后端,原因是该后端引擎会更迅速地进行约束求解,能够和afl++工具进行更好地适配。利用官方提供的测试程序进行分析,一切都运转正常。接下来需要将利用编译好的symcc编译器对我们需要Fuzzing的目标程序进行编译,此时只需要修改编译时的CC标志即可。对freetype以及修改后的ftbench程序均使用symcc编译器编译,成功生成最终目标文件。但是在利用该目标文件做测试时出现了问题。
symcc使用SYMCC_INPUT_FILE环境变量对输入文件进行符号化,在测试时需要手动设置环境变量,将其设置为ftbench的输入文件路径,还需要设置SYMCC_OUTPUT_DIR环境变量,用来保存新生成的测试样本,这里设置为/tmp/output。接着运行ftbench程序,此时屏幕应该输出约束求解信息并且会在/tmp/output目录生成新的测试用例,而实际测试结果是ftbench输出了对应的字体信息,似乎符号执行过程没有生效。
查看官方的声明发现如下:

原因是没有对libc中的函数做符号插桩,这样在执行特定libc函数时就没办法对输入数据进行符号化,因此就不会有符号执行过程,也就不会产生新的测试用例。
因此,如果要使symcc对真实目标程序生效,那么可能需要将所有包含libc的代码都采用symcc编译器进行编译,当程序所需的第三方库或其它依赖库较多时,工作量会非常大,这里暂且不做进一步探索。
笔者还尝试了symcc的兄弟工具symqemu。开发者在symcc的基础上利用qemu来对目标程序运行符号执行过程,这样可以省略编译源码的步骤,对闭源程序做符号执行分析,但在使用过程中还是遇到了问题,运行流程如下:
首先,我们对symqemu进行编译。编译时需要提供编译好的symcc的程序路径。成功后使用symqemu对/bin/cat程序进行测试,发现对未被插桩的/bin/cat应用能够正确执行符号化过程并输出新的测试用例;接着利用symqemu对前面编译好的ftbench进行测试,发现程序卡住,并且一段时间后oom导致应用崩溃。这里笔者猜测是由于程序添加了ASAN相关检测代码,导致symqemu运行时申请了大量内存导致崩溃。重新编译一个纯净版的ftbench程序,再次使用symqemu运行,发现这次程序能够正常运行并输出字体信息,但是没有生成新的测试样例。
经过详细分析发现,symqemu会在do_syscall1函数中,对由环境变量SYMCC_INPUT_FILE指定的输入文件进行符号化,但是目前仅支持通过read系统调用读取的文件进行符号化,如下图所示:
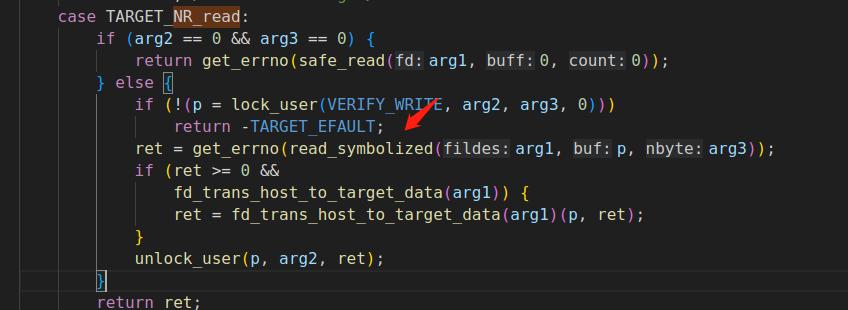
查看支持的符号化函数如下:

接着笔者查看了freetype2中函数FT_Open_Face函数是如何读取输入文件的,经过一番跟踪,最终发现通过mmap函数来读取输入文件:

那么symqemu并没有对mmap函数的调用进行符号化处理,也就无法正常运行符号执行过程,也就无法生成新的测试用例。目前就该问题已经向官方提出issue,希望官方能早日解决。
我们目前仅测试了这两款符号执行工具,但是效果都不理想,后续还会对其它类似工具做尝试,希望最终能找到一款在真实环境下也能运行良好并能辅助Fuzzing的符号执行工具。
结果分析
在经过一段时间的Fuzzing后,笔者利用MSAN编译的程序找到了一些crash,但经过仔细分析后发现这些crash都为误报,MSAN输出如下:

查看af_shaper_get_elem函数,内容如下:
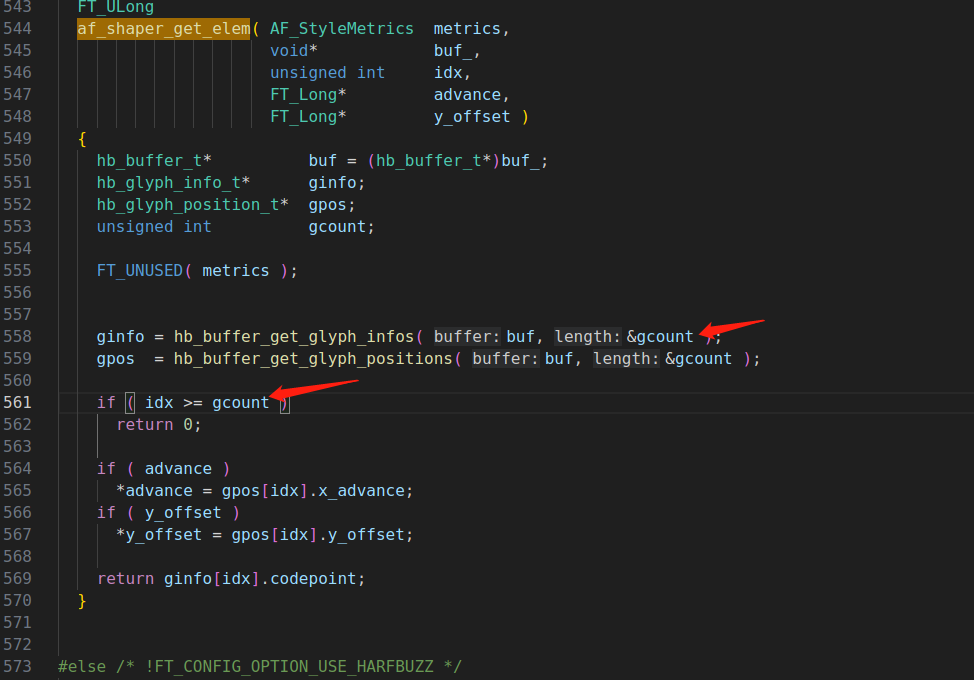
MSAN将gcount视作一个未初始化的变量,但实际在第三方库函数hb_buffer_get_glyph_infos中,该变量已经初始化。由于并未对第三方库harfbuzz进行源码插桩,MSAN可能无法检测出gcount参数已被赋值,所以在561行对gcount的访问就会触发一个crash。
对于这种情况,笔者建议尽可能将所有使用的第三方库通过静态链接的方式打包到目标应用程序中,而不是通过调用动态库的方式去执行函数,否则由MSAN产生的crash可能大部分都是误报。
总结
经过实测,以上的优化措施确实提高了Fuzzing的代码覆盖率,但是依旧未能达到接近100%代码覆盖率的完美状态。这就需要程序员不断地去优化harness程序,找到更合适的样本,以尽可能提高Fuzzing速度。运行Fuzzing、查看Fuzzing状态、分析结果和优化Fuzzing程序,不断地循环这个正反馈过程,最终期望达到一个理想的状态,即尽可能多地探索程序路径使得程序不再出现异常,之后就可以去研究下一个目标了。
在Fuzzing过程中还会遇到一些痛点,如afl会生成大量的无效文件,导致目标应用实际上并没有对输入文件进行深入解析,如此变异后生成的crash样本大部分都是由该原因而崩溃的。如何让afl减少这种对无效路径的探索目前似乎还没有很好的解决方案。之前为了解决afl变异导致生成样本无效的问题时,笔者通过开发一个自定义的变异器来解决该问题,但是这同样需要对变异目标的结构有一定的了解。笔者的一个思路是找到程序在判断输入文件无效后异常退出的代码路径,并且禁止对这部分代码进行插桩,但由于真实软件的复杂性似乎很难做到并且效果未知。当然也可以使用如peach、FormatFuzzer这种工具配合afl++使用,保证变异后的样本是高度结构化的数据,能够通过软件对输入文件格式的校验,这也不失为一种针对文件格式Fuzzing的良好方案。
本次的Fuzzing实战就到这里,整体来说还存在一些不足。未来我们将采用更多的模糊测试工具来进行综合对比测试,并尝试借助AI的能力来解决Fuzzing过程中的痛点,比如用AI来编写harness等等,也期待着更多人的进一步探索。